早在四月份,Meta 就曾表示,它正在开发人工智能行业的第一个项目:一个开源模型,其性能可与 OpenAI 等公司的最佳私有模型相匹配。

Llama 3.1 在某些基准测试中优于 OpenAI 和其他竞争对手。现在,马克·扎克伯格预计 Meta 的人工智能助手的使用量将在未来几个月内超过 ChatGPT。
今天,该模型已经到来。 Meta 正在发布 Llama 3.1,这是有史以来最大的开源 AI 模型,该公司声称该模型在多项基准测试中优于 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet。它还使基于 Llama 的 Meta AI 助手在更多国家/地区和语言中可用,同时添加了可以根据某人的特定肖像生成图像的功能。首席执行官马克·扎克伯格现在预测,到今年年底,Meta AI 将超过 ChatGPT,成为使用最广泛的助手。
Llama 3.1 比几个月前推出的较小的 Llama 3 型号复杂得多。最大的版本有 4050 亿个参数,并使用超过 16,000 个 Nvidia 超昂贵的 H100 GPU 进行训练。 Meta 没有透露开发 Llama 3.1 的成本,但仅根据 Nvidia 芯片的成本,可以肯定猜测其成本为数亿美元。
那么,考虑到成本,为什么 Meta 继续向 Llama 赠送只需要拥有数亿用户的公司批准的许可证呢?在 Meta 公司博客上发表的一封信中,扎克伯格认为开源人工智能模型将超越专有模型,并且其改进速度已经快于专有模型,类似于 Linux 成为为大多数手机、服务器和小工具提供动力的开源操作系统的方式今天。
“行业的拐点,大多数开发人员开始主要使用开源”
他将 Meta 在开源人工智能方面的投资与其早期的开放计算项目进行了比较,他表示,该项目通过让惠普等外部公司在 Meta 建设自己的能力时帮助改进和标准化 Meta 的数据中心设计,为公司节省了“数十亿美元”。展望未来,他预计人工智能也会出现同样的动态,并写道:“我相信 Llama 3.1 版本将成为行业的转折点,大多数开发人员开始主要使用开源。”
为了帮助 Llama 3.1 走向世界,Meta 正在与微软、亚马逊、谷歌、Nvidia 和 Databricks 等二十多家公司合作,帮助开发人员部署自己的版本。 Meta 声称 Llama 3.1 的生产成本大约是 OpenAI 的 GPT-4o 的一半。它发布了模型权重,以便公司可以根据自定义数据对其进行训练并根据自己的喜好进行调整。
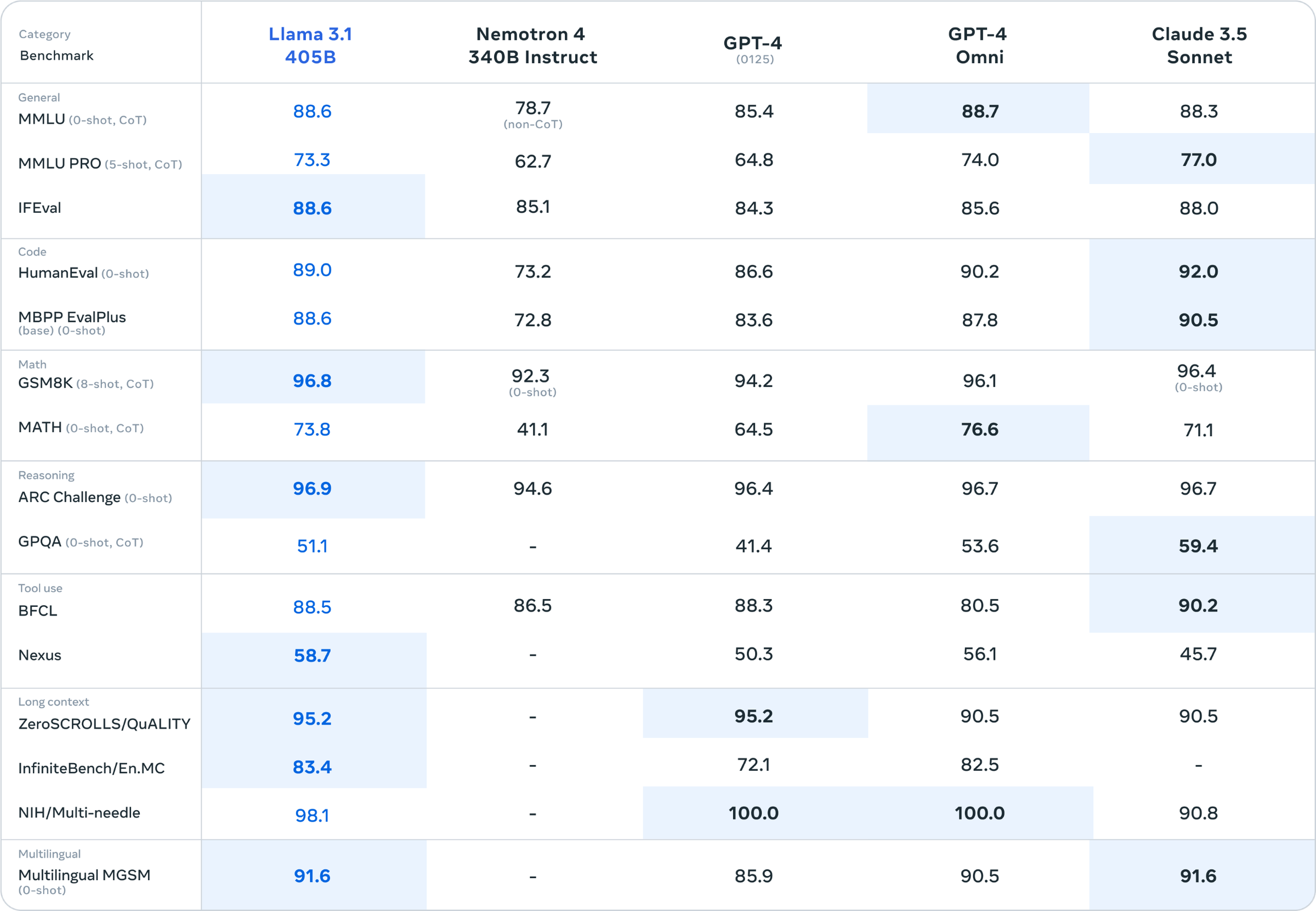
据 Meta 发言人乔恩·卡维尔 (Jon Carvill) 称,Gemini 并未包含在这些基准比较中,因为 Meta 很难使用 Google 的 API 来复制其之前声明的结果。
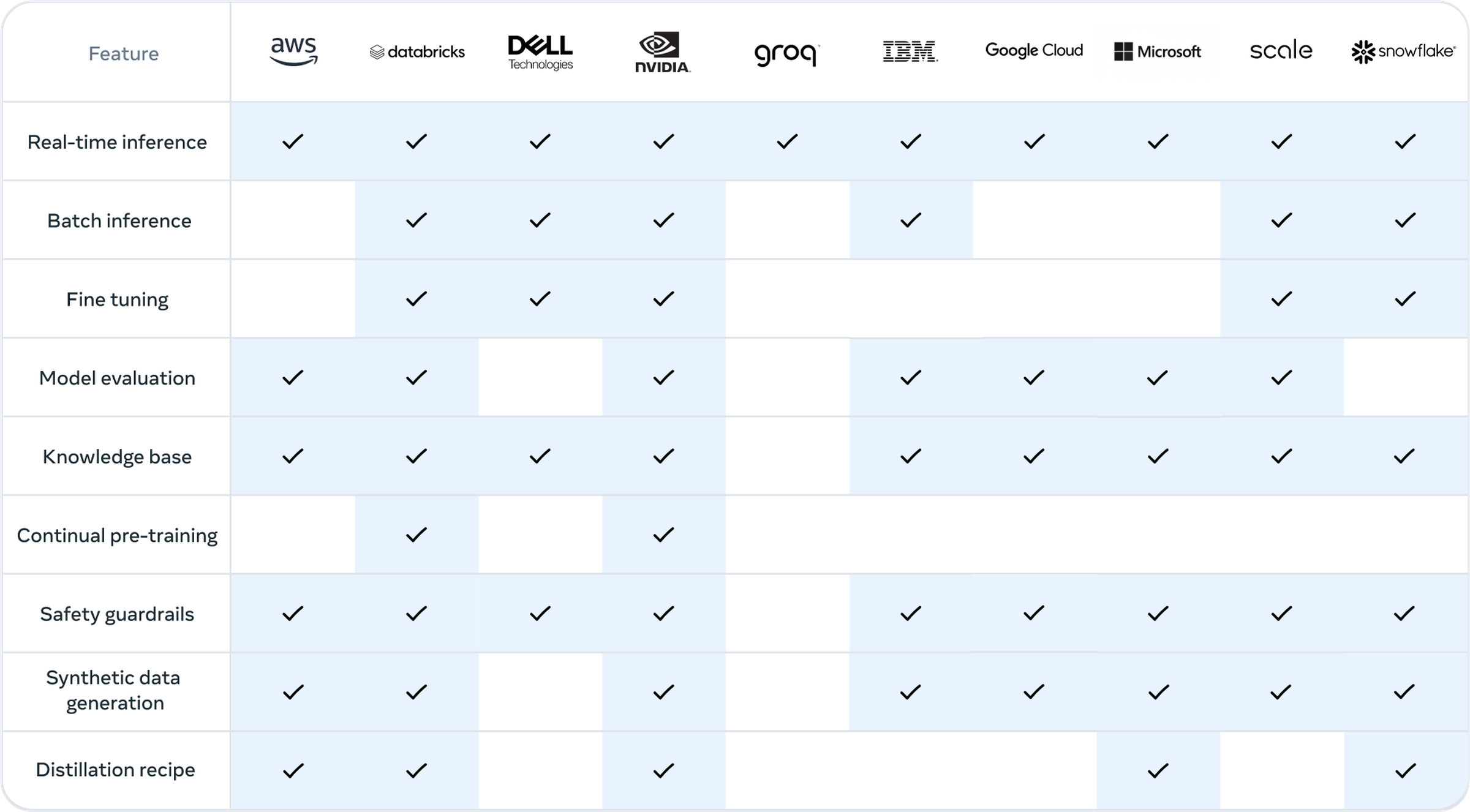
Meta 的主要合作伙伴列表以及他们为部署 Llama 3.1 提供的功能。图表:Meta
毫不奇怪,Meta 并没有透露太多用于训练 Llama 3.1 的数据。人工智能公司的工作人员表示,他们不会披露这些信息,因为这是商业秘密,而批评者则表示,这是一种推迟即将到来的版权诉讼不可避免的冲击的策略。
Meta 会说,它使用了合成数据,或者由模型而不是人类生成的数据,让 Llama 3.1 的 4050 亿参数版本改进了较小的 700 亿和 80 亿版本。 Meta 的生成式 AI 副总裁 Ahmad Al-Dahle 预测,Llama 3.1 将受到开发人员的欢迎,因为它是“小型模型的老师,然后以一种“更具成本效益的方式”进行部署。
当我问 Meta 是否同意行业中模型的高质量训练数据即将耗尽这一日益增长的共识时,Al-Dahle 表示,上限即将到来,尽管它可能比一些人想象的要远。 “我们确实认为我们还有更多的[训练]运行,”他说。 “但这很难说。”
Meta 的 Llama 3.1 红队(或对抗性测试)首次包括寻找潜在的网络安全和生化用例。更努力地测试模型的另一个原因是 Meta 所描述的新兴“代理”行为。
例如,Al-Dahle 告诉我,Llama 3.1 能够与搜索引擎 API 集成,“根据复杂的查询从互联网上检索信息,并连续调用多个工具来完成任务。”他举的另一个例子是要求模型绘制过去五年美国出售的房屋数量。 “它可以为你检索 [web] 搜索并生成 Python 代码并执行它。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI Journey是你的一站式AI工具集导航站点,我们汇集了各种最新、最实用的AI工具,无论你是在工作中还是在日常生活中,都能找到最适合你的AI工具。让人工智能变得触手可及,开始你的AI Journey吧!
