炼丹百科全书
So-VITS-SVC 4.1-Stable 新版整合包使用教程
So-VITS-SVC 项目一直都有在更新,B站视频(指4月26日换源前的视频)里的版本已经比较落后了,并且原版整合包因为做的匆忙,有很多地方做得比较粗糙,所以痛定思痛重写了一个新的真·一站式WebUI整合包。
🤔有什么新的?
- 放弃了各种乱七八糟的脚本文件,数据预处理/推理/训练现可在WebUI一站式解决
- 支持多卡指定GPU训练、多分支一站式整合
- 模块解耦,更多的推理可选参数和可选项(f0均值滤波、声码器增强器、浅扩散)
- 加入了更多防呆手段,尽可能减少报错
- 保持更新,尽可能与项目仓库同步更新
🧐为什么是4.1-Stable?
经过了三个多月的迭代更新,So-VITS的版本号终于向前进了0.1(笑),除了浅扩散和编码器解耦,4.1比起4.0其实没有什么跨越式提升。主要在于4.1-Stable是官方认证的稳定分支,除此之外还有一个4.1-Latest分支,那里会有更多仍在开发中的实验性新功能。因为出BUG的概率很大,所以本整合包只会同步更新Stable分支的内容。
📚更新日志(什么时候可以折叠啊这一块好长的)
2023.05.20 v2.1.3 (NEWEST)
- 修复了训练聚类模型的BUG
- 修复了浅扩散推理时无法正确加载采样器的BUG
2023.05.20 v2.1.2
- 修复了一个会导致无法加载模型的BUG
2023.05.20 v2.1.1
- 修复了无法训练聚类模型的BUG,新增GPU训练聚类模型的可选项
- 修复了无法继续训练扩散模型的BUG
- 修复了其他的一些BUG
2023.05.19 v2.1.0
- 🚩新增浅扩散功能,可显著改善电音底噪问题
- 新增hubertsoft编码器底模
- 修复了一些BUG和逻辑
本次更新较为重要,请仔细阅读文档内的v2更新指南,确保平稳更新。
2023.05.15 v2.0.0 (NEWEST)
- 加入了训练时的特征编码器和f0预测器可选项
- 新增模型压缩工具,可以将模型体积无损压缩至200M左右
- 重构了部分代码,与项目仓库同步,将编码器与模型解耦
2023.05.13 v1.5.1
- 修复了一个导致无法训练的BUG
2023.05.13 v1.5.0
- 加入了推理时的f0预测器可选项
- 加入了文本转语音的部分中文方言支持(东北话、陕西话、粤语)
2023.05.12 v1.4.2
- 修复了一些无伤大雅的BUG,加入对P4显卡的识别
- 优化了一些交互逻辑
2023.05.05 v1.4.1
- 修复了一个致命BUG,会导致重新训练时无法正确备份先前的工作进度
- 修复了其他的BUG和优化了逻辑
2023.05.02 v1.4.0
- 🚩新增文本转语音功能(edge_TTS)
- 新增数据集智能切片小工具,无需调参数即可一键制作时长符合要求的数据集
- 修复了一些BUG
2023.04.28 v1.3.2
- 修复了特定情况下训练Vec768分支无法正确加载模型和配置文件的BUG
- 修复了其他的一些BUG
2023.04.27 v1.3.1
- 修复了Vec768-Layer12分支训练时无法正确识别说话人的BUG
- 修复了一些无关紧要的BUG
2023.04.26 v1.3.0
- 🚩新增Vec768-Layer12(4.0v3)分支支持,该分支在小规模测试下质量和上限均优于原版
- 新增音频批量推理功能
2023.04.25 v1.2.1
- 修复了一些BUG
- 新增f0均值滤波的过滤阈值可选项
2023.04.24 v1.2.0
- 新增多模型声线融合功能
- 新增 Onnx 批量转换
- 优化了 WebUI 界面
2023.04.09 v1.1.0
- 整合了python环境,不需要再装python了(码的配环境配了一下午)
- 🚩新增NSF-HiFiGAN声码器增强器功能
- 新增了一些推理/训练可选项
2023.04.06 v1.0.0
- WebUI一站式整合
- 🚩f0均值滤波(缓解哑音问题)
- 更多推理可选项
⚖️许可证声明和作品简介模板
So-VITS-SVC仓库与本整合包现已换用BSD 3-Clause许可,即日起使用本整合包或直接使用原项目仓库产出的作品,需遵循以下协议条款:
- 未经授权同意,禁止在音视频网站发布的作品中标注项目仓库地址、仓库作者、贡献者、整合包作者的信息。
- 必须在作品中标注免责声明,免去仓库作者、贡献者、整合包作者对该作品一切后果的责任。
作品简介模板
Cover/原唱: [使用的输入源音声来源]
音声来源:[训练集音声来源]
免责声明:本作品仅作为娱乐目的发布,可能造成的后果与使用的音声转换项目的作者、贡献者无关。
🚧v2 整合包更新指南(及旧模型兼容迁移)
为了方便So-VITS-SVC后续更大规模的更新,项目对部分代码进行了重构,将部分模块与模型解耦,同时实现了多分支、多编码器完全整合。由于项目本体改动较大,本整合包也对部分代码进行了同步重构,并加入了新功能。现在你可以自由选择训练时使用的特征编码和f0提取,进一步提升模型质量;多分支(v1/vec768/hubertsoft)无缝整合,可以在整合包内自由切换推理。但由于改动较大,v1.x 版本整合包将无法通过增量更新升级到 v2.0 及后续版本。同时,先前训练的模型需要进行一些简单的操作才能够兼容 v2 整合包。
从 v1.x 升级到 v2
- 下载完整的最新 v2 整合包,并解压至任意目录
- 旧模型迁移:请按本文档最后的🥰外部模型如何迁移到新版整合包?内的指引迁移模型
- 模型兼容性修改:在configs文件夹内用文本编辑器打开模型的对应配置文件,从最后往上找,找到 “n_speakers”项,在这一行最后添加一个英文逗号(“,”),然后添加新的两行:
“speech_encoder”: “vec256l9”, # 如果是vec768模型,这一项改成”vec768l12″
“speaker_embedding”: false
↓像这样(“speaker_embedding”最后不要有英文逗号)
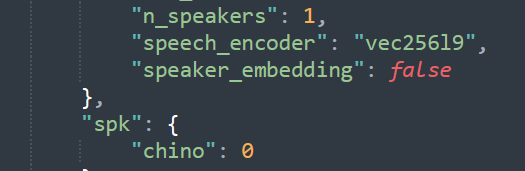
完成了!其实很简单,对吧?
如果你还是看不懂该怎么升级,或者对这一版本的新功能没有需求,也可以不更新。但后续So-VITS的所有重大更新都将基于2.0版本的整合包,因此你到时候还得走一遍更新流程。
🤗下载地址
🎉完整整合包(v2.1.3)
百度网盘:https://pan.baidu.com/s/12u_LDyb5KSOfvjJ9LVwCIQ?pwd=g8n4 提取码:g8n4
Google Drive: 更新中
🚀增量更新(v2.1.3)
直接替换整合包内的文件
⚠️ v 2.0.0 以下版本无法通过增量包更新至 v2.1,请下载完整整合包
v2.1.3:https://pan.baidu.com/s/1N-47gaAFE1Ewd4hrOQEu8A?pwd=yryv 提取码:yryv
🧭底模DLC
整合包内自带预训练模型(底模),但Vec768l12编码器目前有一个更强的底模,你可以自行下载并替换原来的底模。只要将下载的 clean_G_320000.pth 和 clean_D_320000.pth 分别改名为 G_0.pth 和 D_0.pth,替换到整合包内的 pre_trained_model/768l12 下同名文件即可。
📢使用教程
Step 1: 安装Python 3.8.9
Python环境已经整合到整合包中,现在无需安装Python也可以使用新版整合包了。(你问我为什么之前不整合?问就是懒🤣)
Step 2: 解压整合包
将整合包解压到电脑硬盘中(路径中尽量不要包含中文),整合包内已经搭建好了运行所需的所有环境依赖,你无需自己手动搭建环境。
Step 3: 准备数据集
数据集的准备和旧版没有任何区别,请参考BV1H24y187Ko中的指引自己准备数据集。
5.2日更新:现在你可以在WebUI中进行数据集音频切片了。在WebUI中整合了一个小工具,可以无需调参一键式切片,确保你的数据集不会出现过长或过短的音频。
Step 4: 在WebUI中进行数据预处理/训练
将准备好的数据集放置在 .\dataset_raw\ 文件夹中,确保文件夹结构正确:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───…
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───…
└───xxx7-xxx007.wav
打开启动WebUI.bat,选择上方“训练”标签卡,进入训练设置界面:
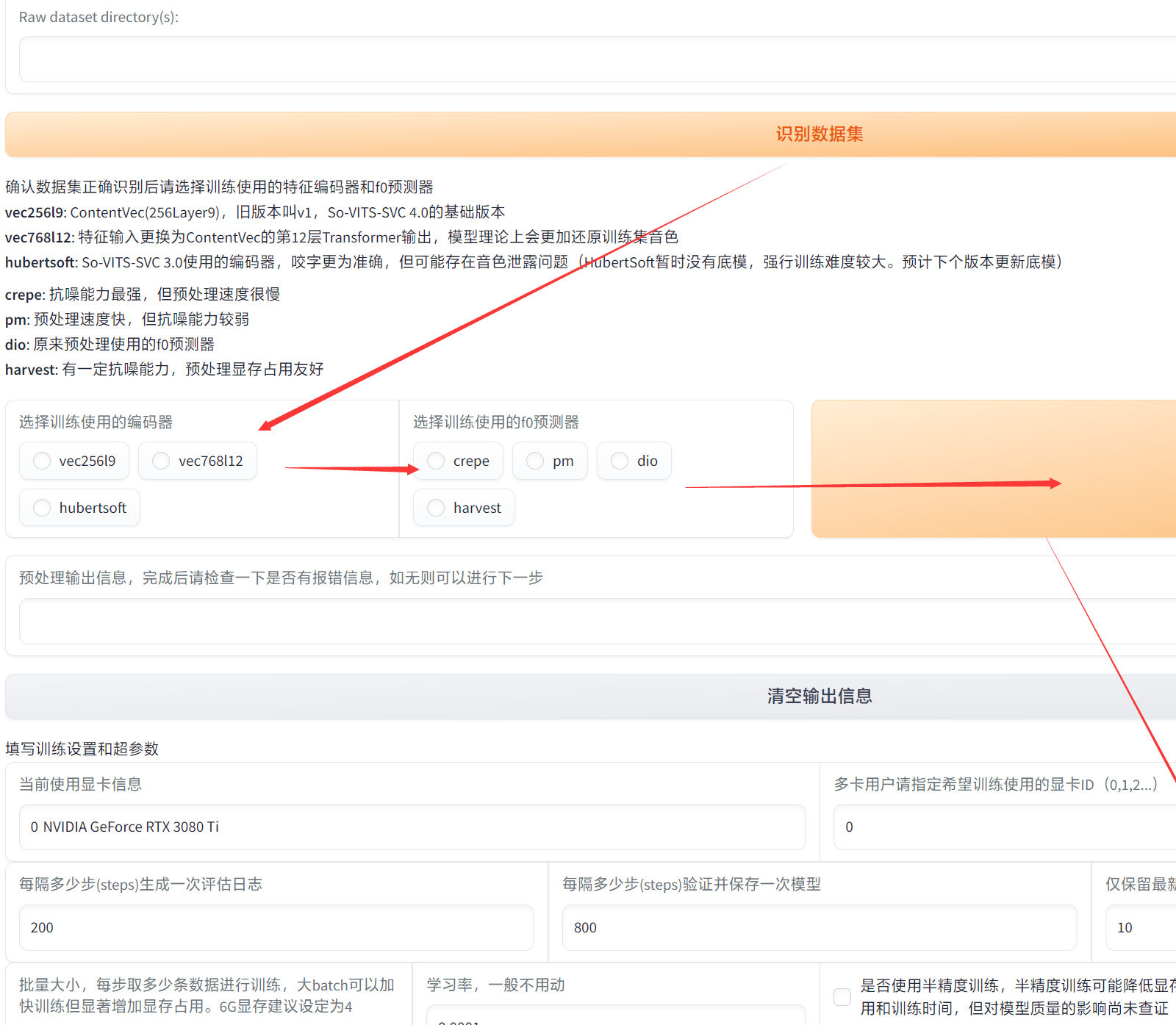
(很简单啊,一看就懂了)
遇到WebUI卡死请参照以下解决方案:关闭代理/换浏览器(Chrome为佳)/清除浏览器缓存/如果浏览器自带网页翻译也要关闭
一些说明:
- 评估日志和保存模型均是按照步数(steps)而非轮数(epoch)来计算的,默认的数值比较常用。步数和轮数的关系是:steps = epoch * (数据集数量/batch size)
- 批量大小(batch_size)极度影响显存占用。如果遇到CUDA out of memory报错请首先调低batch size,如果不行再考虑升级显卡驱动、CUDA驱动。本环境在CUDA 11.7和12.0中测试稳定
- 半精度训练(fp16)是一个比较玄学的参数,如果你不知道这是干嘛的还是保持关闭就好
- 多卡用户如果要指定某张显卡用于训练的话,可以使用 nvidia-smi 命令来查看显卡的系统编号,但是英伟达的编号分配逻辑就是依托,很容易出现指定不到你想选的那张显卡的问题。默认0是不会出错的
- 不要问我怎么才算训练好了,用整合包的启动tensorboard.bat来查看损失函数值收敛趋势,tensorboard里还可以试听当前模型的测试音频,但是测试音频不代表模型的实际产出。你觉得差不多训练好了就可以手动中止了。
Step 5: 在WebUI中进行推理
快来试试刚刚出炉的模型吧!
新版整合包的推理和旧版除了多出来一些可选项以外没有任何区别。仍然可以参考BV1H24y187Ko中的指引来操作。一些新的参数在WebUI中也有很详细的说明,你可以自己试试看。
新版WebUI在生成音频的时候会将文件自动保存在results文件夹内,你无需一个个手动下载了。
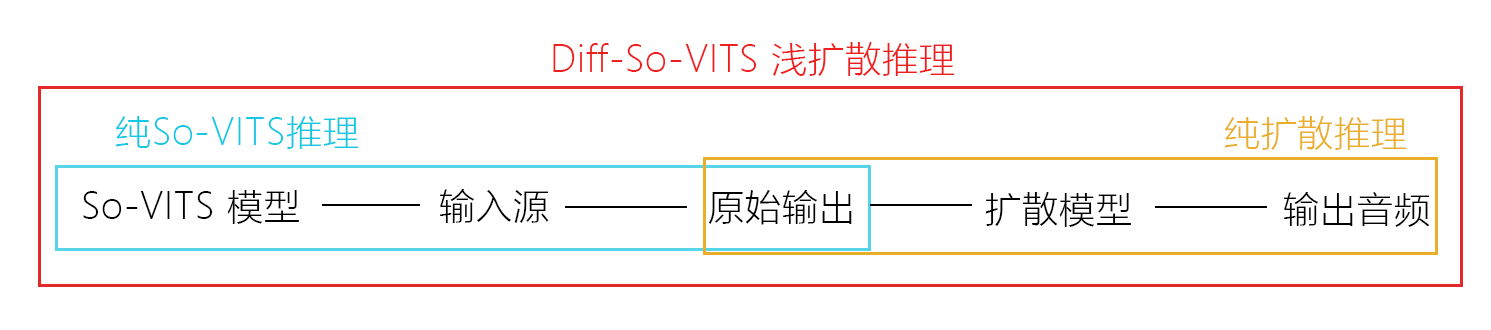
⏭关于浅扩散(Shallow Diffusion)
So-VITS 4.0近期的一个重大更新就是引入了浅扩散(Shallow Diffusion)机制,将So-VITS的原始输出音频转换为Mel谱图,加入噪声并进行浅扩散处理后经过声码器输出音频。经过测试,原始输出音频在经过浅扩散处理后可以显著改善电音、底噪等问题,输出质量得到大幅增强。
要使用浅扩散机制,你必须在原有的数据集上新训练一个扩散模型,并确保配置文件中的说话人名称与So-VITS模型的配置文件一致。扩散模型与So-VITS模型是独立的,得益于浅扩散机制的向下兼容性,你仍然可以只使用其中任意一个模型进行推理,或者同时使用So-VITS和扩散模型进行完整的浅扩散推理。
🥰外部模型如何迁移到新版整合包?
把G_模型和Kmeans聚类模型放到新版整合包的以下目录:
.\logs\44k
把对应的config.json(在configs文件夹内)放置到新版的以下目录:
.\configs
把扩散模型放到新版整合包的以下目录:
.\logs\44k\diffusion
不太建议将旧版整合包未完成的训练转移到新版,因为两个包的环境依赖有所不同,容易出现意料之外的问题。
😪未来更新内容(有想要的功能或者BUG反馈可以在这里添加批注)
- 音频批量推理
- 文本转语音(edgetts)
- onnx批量转换
- 整合数据集音频切片
- 加入So-VITS-SVC-vec768-layer12 的分支支持
- 多模型音色融合
……
So-VITS-SVC 4.0云端训练教程
https://www.bilibili.com/video/BV1324y1572U/
感谢@风缘
目前AutoDL云端镜像已经与本整合包同步更新,基本能实现新版整合包的绝大多数功能。感谢云端镜像作者@麦哲云
请在社区镜像选择so-vits-svc-v4-Webui:v11即可使用最新镜像。
DDSP-SVC 3.0 (DDDSP, D3SP) 整合包及训练/推理教程
🤔DDSP-SVC 3.0 (D3SP) 是什么?
DDSP-SVC 是一个相对年轻的音声转换项目,相较于常用的So-VITS和更早的Diff-SVC,DDSP在训练推理速度和配置要求上都可以说是全面优于前两个项目,一般来说只要有一张2G以上显存的N卡,花上一两个小时就可以训练完成,大大降低了AI变声的门槛。当然,带来的牺牲就是其原本的转换效果是不太尽人意的。
但是最近DDSP项目迭代到了3.0版本,在原有的基础上加入了浅扩散机制,将DDSP输出的质量较低的音频梅尔谱图输入扩散模型进行浅扩散处理,输出梅尔谱图并通过声码器转换为高质量音频,使得转换效果大幅提升,在部分数据集上可以达到媲美So-VITS的效果。因此DDSP-SVC 3.0也可以称为D3SP(DDSP with Diffusion, DDDSP, 带带大涩批)。
戳这里:https://www.bilibili.com/video/BV1rs4y1Q7BQ/
转载自:炼丹百科全书 (qq.com)
相关文章
